
Enhancing Mass Spectrometry Data Analysis with Machine Learning and Data Science
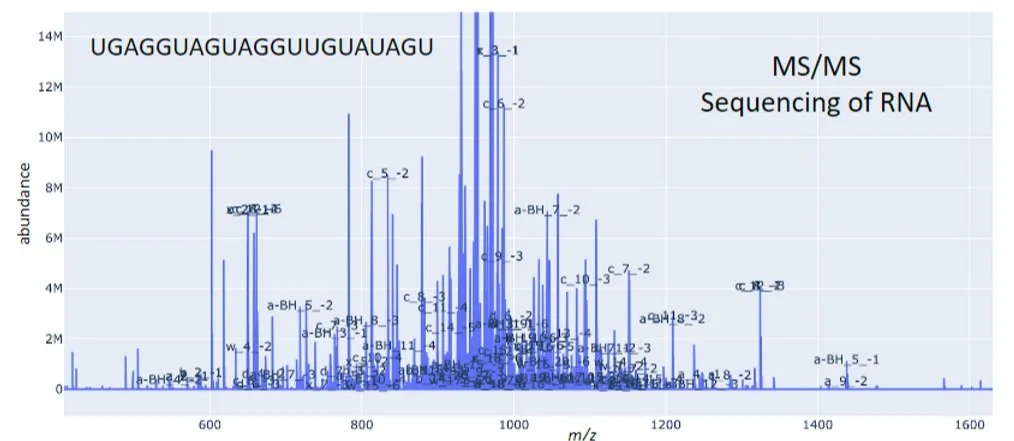
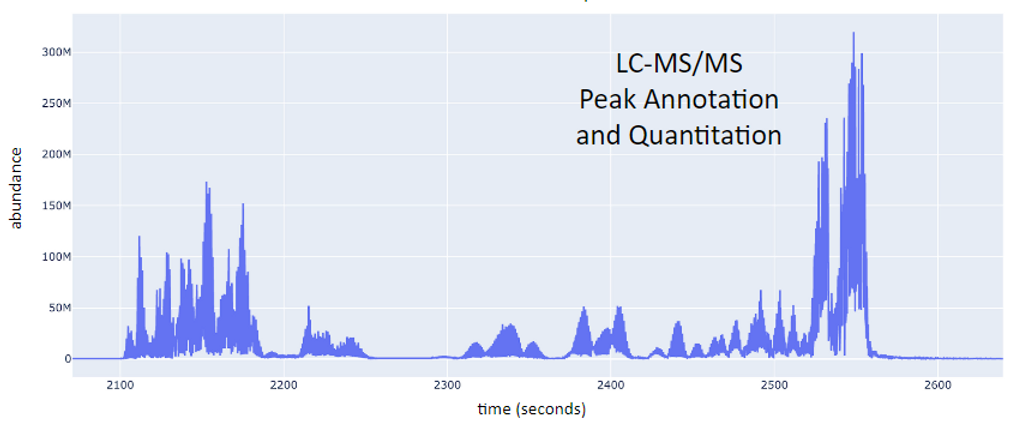
STATIGEN AI recently collaborated with a startup specializing in mass spectrometry data analysis, to overcome several challenges using machine learning and data science techniques. This case study outlines the key challenges faced by the startup and how STATIGEN AI's solutions delivered significant improvements in data analysis accuracy and efficiency.
Challenge 1: Navigating High-Dimensional Data
With mass spectrometry datasets, dealing with high-dimensional data is the norm. However, distinguishing the relevant features from the irrelevant ones in such data sets is a formidable task. The challenge lay in the automated and accurate selection of features, which would feed into the machine learning model.
Solution: STATIGEN AI implemented a dual strategy to navigate through this high-dimensional space. First, Recursive Feature Elimination (RFE) methodology was utilized. This feature ranking method fits the model, ranks features by importance, discards the least important features, and repeats the process. Concurrently, Feature Importance Ranking was employed, which calculates the importance of each feature using metrics such as the Gini importance. These two robust techniques enabled STATIGEN AI to build an accurate machine learning model, enhancing its performance while dealing effectively with high-dimensional data.
Challenge 3: Working with Sparse Data
Being a startup, the company was dealing with sparse datasets, requiring synthetic data to supplement their training data. However, implementing Generative Adversarial Networks (GANs) for synthetic data generation is a complex process that requires careful validation.
Solution: STATIGEN AI utilized GANs for synthetic data generation, ensuring the validity and quality of the synthetic data by introducing a rigorous validation process. This process involved continuous comparison of the cumulative distribution functions (CDFs) of the original and generated data to maintain their distributional similarity, ensuring the synthetic data was representative of the real-world data.
Challenge 5: Scalability of Machine Learning Pipeline
As the startup’s data volumes and complexity grew, their existing machine learning pipeline was unable to scale effectively, leading to performance bottlenecks and limiting their ability to conduct complex data analysis.
Solution:
STATIGEN AI designed and implemented a scalable machine learning pipeline using TensorFlow, PyTorch, and Apache Spark. This enabled startup to efficiently handle larger data sets and conduct more complex analyses without sacrificing speed or incurring excessive costs.
Conclusion: STATIGEN AI's expertise in machine learning and data science enabled the startup to overcome numerous challenges inherent in mass spectrometry data analysis. By leveraging advanced techniques and providing tailored solutions, STATIGEN AI delivered improved accuracy, efficiency, and scalability for the mass spec startup’s data analysis needs.
Challenge 2: Purging Noise from Data
Inherent noise and outliers in Startup M's raw mass spectrometry data was impeding the accuracy of their predictive models. This challenge was attributed to issues like sensor drift and electromagnetic noise that lead to unreliable insights.
Solution: STATIGEN AI addressed this challenge by employing a comprehensive noise reduction strategy. Utilizing deep learning differential models to model the underlying distribution of the noise, and differential filtering techniques to suppress unwanted noise, the data quality was substantially improved. Furthermore, robust statistical methods like Tukey's Fences helped identify and handle outliers, thereby ensuring better input data quality for machine learning models
Challenge 4: Data Visualization for Large Datasets
The cumbersome task of sifting through bulky mass spectrometry data was impeding the efficiency of Startup M's scientists.
Solution: STATIGEN AI developed an intuitive data visualization tool tailored to startup’s needs. The solution enabled the scientists to tag unidentified peaks, providing them with the capability to build a collective enterprise knowledge base, which significantly enhanced their data analysis process.
Challenge 6: Data Engineering for Scale and Performance
As Startup M's data volumes and complexity grew, their scientists wanted to overlay identified and tagged peaks from multiple mass spectrometry data files as well as annotate visual graphs to share with other scientists. This required a data store that could store metadata as well as comparison data between various visualizations for efficient storage and faster retrieval.
Solution: STATIGEN AI designed and implemented a scalable data store on AWS RDS, RedShift. This enabled Startup M to efficiently store derived as well as user generated metadata about multiple mass spectrometry data files which in turn facilitated them to conduct interesting side-by-side analyses.